
IT之家1月27日消息,DeepSeek今日公布了其最新一代文档识别模型DeepSeek-OCR2。很显然,该模型是在DeepSeek-OCR的基础上升级而来,核心变化集中在视觉编码器设计上。
研究团队提出了一种名为DeepEncoderV2的新型编码器结构,这项技术突破源于对传统视觉语言模型处理方式的重新思考,旨在让机器更贴近人类的视觉阅读逻辑。
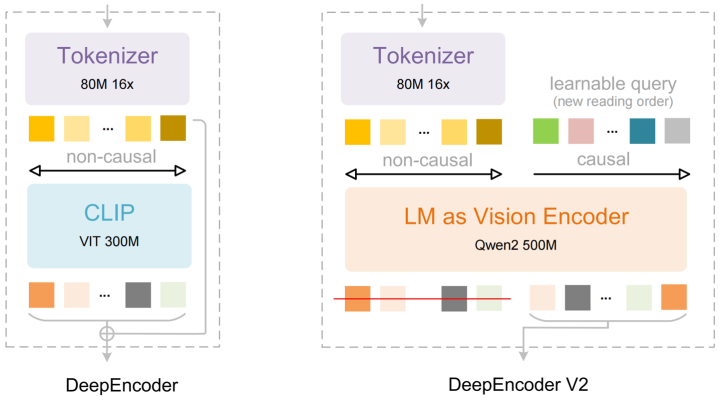
在传统的视觉语言模型中,图像通常会被切分为若干视觉token,并按照从左上到右下的固定栅格顺序送入模型处理。这种方式虽然实现简单,但与人类在阅读文档、表格或公式时基于语义和逻辑关系进行跳跃式浏览的方式并不一致。
DeepSeek论文指出,尤其在版式复杂的文档场景中,视觉元素之间往往存在明确的逻辑先后关系,仅依赖空间顺序可能限制模型对内容结构的理解能力。
DeepSeek-OCR2的改进重点在于引入“视觉因果流”的概念。在DeepEncoderV2中,研究团队用一种类语言模型结构替代了原先基于CLIP的视觉编码模块,并在编码器内部引入可学习的“因果流查询token”。这些查询token通过定制化的注意力机制,在保留视觉token全局双向注意力的同时,自身采用因果注意力,只能访问已有信息,从而在编码阶段对视觉token的顺序进行动态重排。最终,只有经过因果重排后的查询token会被送入后续的语言模型解码器,用于生成识别结果。
在整体架构上,DeepSeek-OCR2仍然沿用了编码器—解码器的基本范式。图像首先经过一个视觉tokenizer,被压缩为较少数量的视觉token,再由DeepEncoderV2进行语义建模和顺序重组,最后交由一个基于混合专家架构(MoE)的语言模型解码。
DeepSeek论文指出,该设计在不显著增加解码负担的前提下,将单页文档所使用的视觉token数量控制在256到1120之间,与前代模型及同类系统的资源开销保持在相近水平。
在实验评估方面,研究团队选用了OmniDocBenchv1.5作为主要测试基准。该基准涵盖多种类型的中英文文档,包括学术论文、杂志、报告等,重点考察文本识别、公式解析、表格结构还原以及阅读顺序等指标。
测试结果显示,在视觉token上限更低的情况下,DeepSeek-OCR2的整体得分达到91.09%,相较DeepSeek-OCR提升了3.73%。其中,与文档阅读顺序相关的编辑距离指标下降较为明显,显示模型在处理文档逻辑结构方面取得了改进。
IT之家注意到,论文还给出了模型在实际应用场景中的表现对比。在在线OCR服务和批量PDF预处理等生产环境中,由于缺乏人工标注作为参考,研究团队以输出重复率作为质量指标。结果显示,DeepSeek-OCR2在这两类数据上的重复率均低于前代模型,表明其在真实数据分布下具有更稳定的输出表现。
